임베딩(Embedding)
임베딩은 텍스트, 이미지, 동영상 등 비정형 데이터를 컴퓨터가 이해하고 연산할 수 있도록
고차원 공간의 벡터(숫자 배열)로 변환하는 기술입니다. 핵심은 데이터 간 의미적 유사성을 벡터 간 거리로
표현하는 것으로, 비슷한 의미를 가진 데이터는 가까운 위치에, 다른 의미의 데이터는 먼 위치에 배치됩니다.
1임베딩(Embedding) 정의
임베딩(Embedding)이란?
임베딩은 텍스트의 의미를 숫자 형태(벡터)로 변환하여 AI가 단어가 아닌 ‘의미’를 이해할 수 있도록 만드는 기술입니다.
기존 검색은 단어가 정확히 일치해야 결과를 찾을 수 있었지만, 임베딩은 의미가 비슷한 문장도 서로 가깝게 인식합니다.
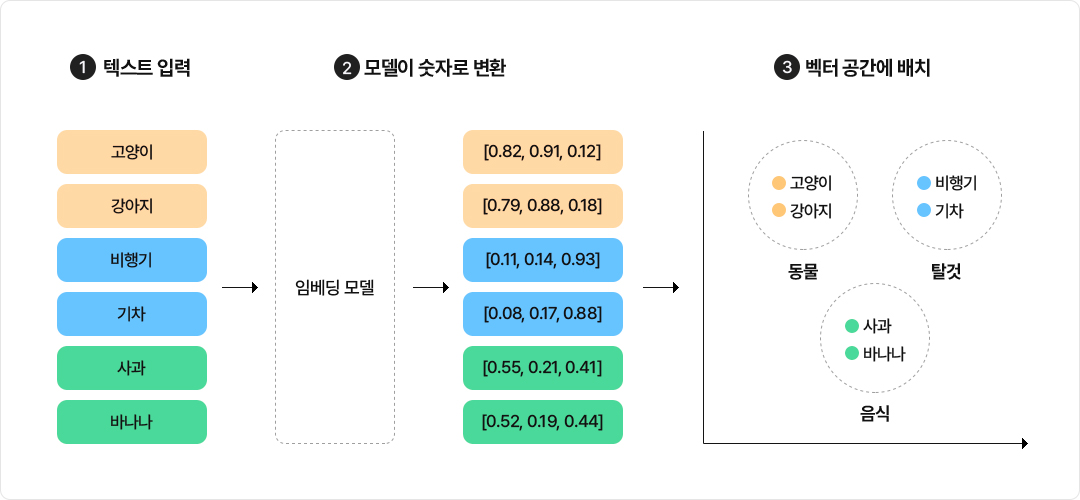
위 그림은 임베딩을 세 단계로 나눠서 보여줍니다.
- 1텍스트 입력 : 사람이 이해하는 자연어 단어 또는 문장들을 그대로 입력합니다.
- 2모델이 숫자로 변환 : 모델이 각 단어의 의미를 숫자 배열(벡터)로 표현합니다. 비슷한 의미의 단어는 비슷한 숫자 패턴을 갖습니다.
- 3벡터 공간에 배치 : 숫자들을 좌표로 쓰면, 비슷한 단어들이 자연스럽게 가까이 뭉치게 됩니다. 고양이·강아지는 자연스럽게 가까운
위치에 배치되어 동일한 그룹에 속하는 것처럼 보입니다. 비행기·기차는 자기들끼리 별도의 그룹을 형성하는 방식으로 배치됩니다.
2임베딩 적용 전/후 비교
1. 임베딩 미적용 - 키워드 기반 검색의 구조적 한계
-
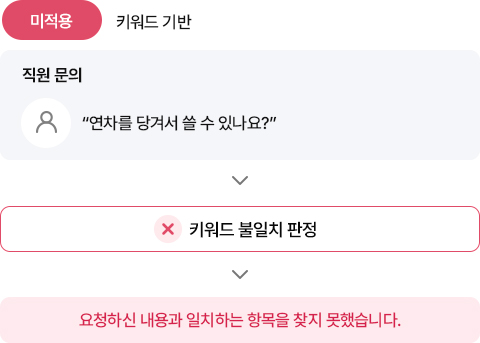
표현이 조금만 달라져도 검색에 실패하는 이유
왼쪽의 임베딩 미적용 예시를 보면, 키워드 기반 시스템은 입력된 단어와
사내 정책 문서에 등록된 단어가 정확히 일치할 때만 결과를 반환합니다.
"연차", "선사용", "당겨쓰기" 중 어느 표현도 문서에 등록되지 않았다면
응답에 실패합니다. 임직원마다 다른 표현 방식을 시스템이 수용하지 못하는
구조적 한계입니다.
2. 임베딩 적용 - 의미 기반 검색의 작동 방식
-
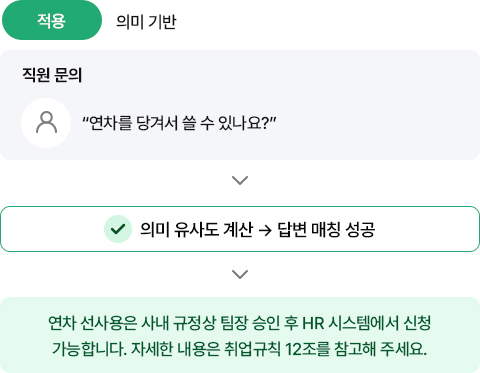
표현이 달라도 의도를 정확히 파악합니다
이번에는 임베딩 적용 예시를 보면, 임베딩 기반 시스템은 임직원의
질문을 벡터로 변환한 뒤, 사전에 임베딩 처리된 사내 정책 문서 전체와
코사인 유사도를 계산합니다.
"당겨서 쓰다"는 표현이 "선사용", "연차 조기 사용"과 의미적으로
가깝다는 것을 수치로 인식해 가장 연관성 높은 정책 조항을 자동으로
반환합니다.* 코사인 유사도 (Cosine Similarity) : 코사인 유사도는 두 벡터 간의 각도를 기준으로 방향의
유사성을 비교하여, 값이 클수록 의미적으로 더 유사함을 나타내는 계산 방식입니다.
3. 한눈에 보는 비교표
3임베딩 활용 예시 – 기업 내부 챗봇
1. 임베딩 기반 기업 내부 챗봇의 처리 구조
챗봇이 임직원의 질문을 수신하면, 임베딩 모델은 해당 문장 전체의 의미를 고차원 벡터로 인코딩합니다.
이후 사전에 임베딩 처리된 사내 규정집, 취업규칙, 복리후생 안내서 등 정책 문서 전체와 벡터 유사도를 비교해 의미적으로 가장
근접한 항목을 실시간으로 탐색합니다. 수백 개의 문서가 존재하더라도 이 연산은 수십 밀리초(ms) 내에 처리됩니다.
2.표현이 달라도 같은 의도를 찾아내는 챗봇의 임베딩
-
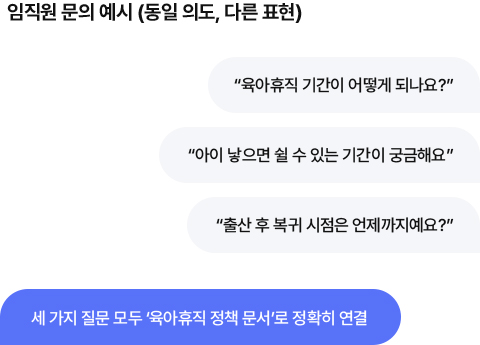
사용자(임직원)는 같은 정책을 수십 가지 방식으로 질문합니다.
이미지 속 임직원 문의 예시를 보면, 임직원의 다양한 표현의 질문을
챗봇은 같은 의도로 찾아내 정확한 답변문서로 연결합니다.

-
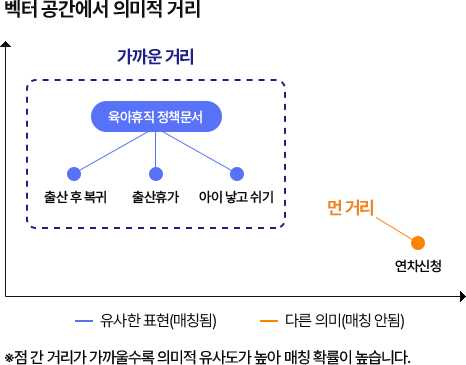
다른 표현, 비슷한 의미를 찾아가는 벡터 공간
사용자(임직원)의 질문의 표현이 입력된 후 임베딩 과정이 적용되며
벡터 공간에서 의미적 거리를 찾아 나갑니다.
이 과정이 진행되며 기존의 키워드 기반의 질문보다 더 높은 매칭 확률로
답변을 정확하고 빠르게 처리합니다.
키워드의 한계를 넘어, 의미를 이해하는 임베딩 경험을 제공합니다.

